

Prof. Yeseong Kim from the Department of Information and Communication Engineering, DGIST
Software and hardware overview of DUAL based on Hyperdimensional Computing
Scientists at DGIST in Korea, and UC Irvine and UC San Diego in the US, have developed a computer architecture that processes unsupervised machine learning algorithms faster, while consuming significantly less energy than state-of-the-art graphics processing units. The key is processing data where it is stored in computer memory and in an all-digital format. The researchers presented the new architecture, called DUAL, at the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture.
“Today’s computer applications generate a large amount of data that needs to be processed by machine learning algorithms,” says Yeseong Kim of Daegu Gyeongbuk Institute of Science and Technology (DGIST), who led the effort.
Powerful ‘unsupervised’ machine learning involves training an algorithm to recognize patterns in large datasets without providing labelled examples for comparison. One popular approach is a clustering algorithm, which groups similar data into different classes. These algorithms are used for a wide variety of data analyses, such as identifying fake news on social media, filtering spam in our e-mails, and detecting criminal or fraudulent activity online.
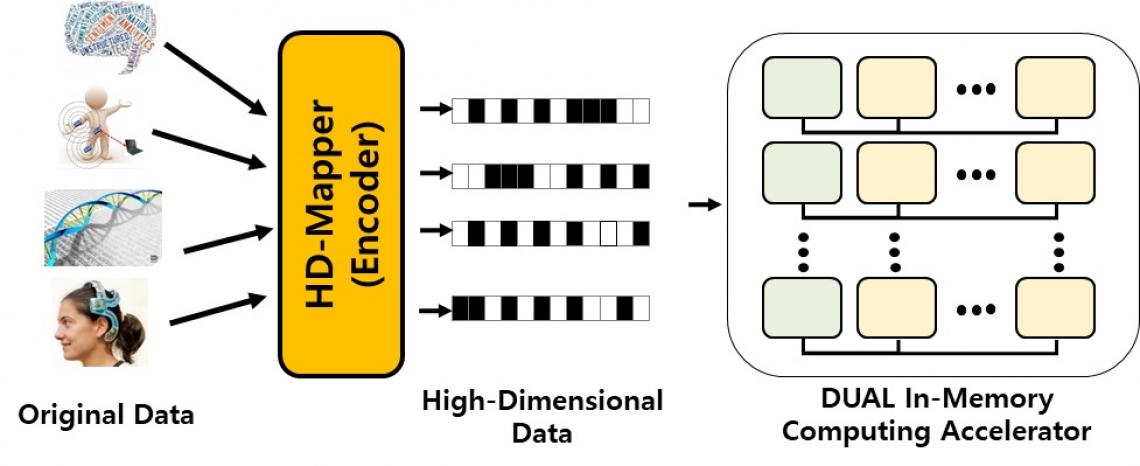
“But running clustering algorithms on traditional cores results in high energy consumption and slow processing, because a large amount of data needs to be moved from the computer’s memory to its processing unit, where the machine learning tasks are conducted,” explains Kim.
Scientists have been looking into processing in-memory (PIM) approaches. But most PIM architectures are analog-based and require analog-to-digital and digital-to-analog converters, which take up a huge amount of the computer chip power and area. They also work better with supervised machine learning, which includes labelled datasets to help train the algorithm.
To overcome these issues, Kim and his colleagues developed DUAL, which stands for digital-based unsupervised learning acceleration. DUAL enables computations on digital data stored inside a computer memory. It works by mapping all the data points into high-dimensional space; imagine data points stored in many locations within the human brain.
The scientists found DUAL efficiently speeds up many different clustering algorithms, using a wide range of large-scale datasets, and significantly improves energy efficiency compared to a state-of-the-art graphics processing unit. The researchers believe this is the first digital-based PIM architecture that can accelerate unsupervised machine learning.
“The existing approach of the state-of-the-arts in-memory computing research focuses on accelerating supervised learning algorithms through artificial neural networks, which increases chip design costs and may not guarantee sufficient learning quality,” says Kim. “We showed that combining hyper-dimensional and in-memory computing can significantly improve efficiency while providing sufficient accuracy.”
